ResNet 网络结构原理与应用实践
深层网络一定比浅层网络更强吗?ResNet 用一条「抄近路」的加法,把这个问题答得很干脆。
为什么要 ResNet
卷积神经网络越深,理论上能表达的函数越复杂。ImageNet 竞赛早期,大家拼命堆层数——VGG 到了 19 层,GoogLeNet 用 Inception 模块控制参数量。但很快遇到一个反直觉的现象:
网络加深后,训练误差和测试误差反而一起上升。
这不是过拟合(过拟合是训练误差低、测试误差高),而是优化本身出了问题:更深的网络在同样训练条件下,表现还不如浅一点的版本。何恺明等人在 2015 年把这叫 degradation problem(退化问题)。
ResNet(Residual Network,残差网络)的核心思路是:与其让每一层从零学一个完整映射,不如让层去学「输入和输出之间的差值」,也就是 残差(residual)。
残差块在做什么
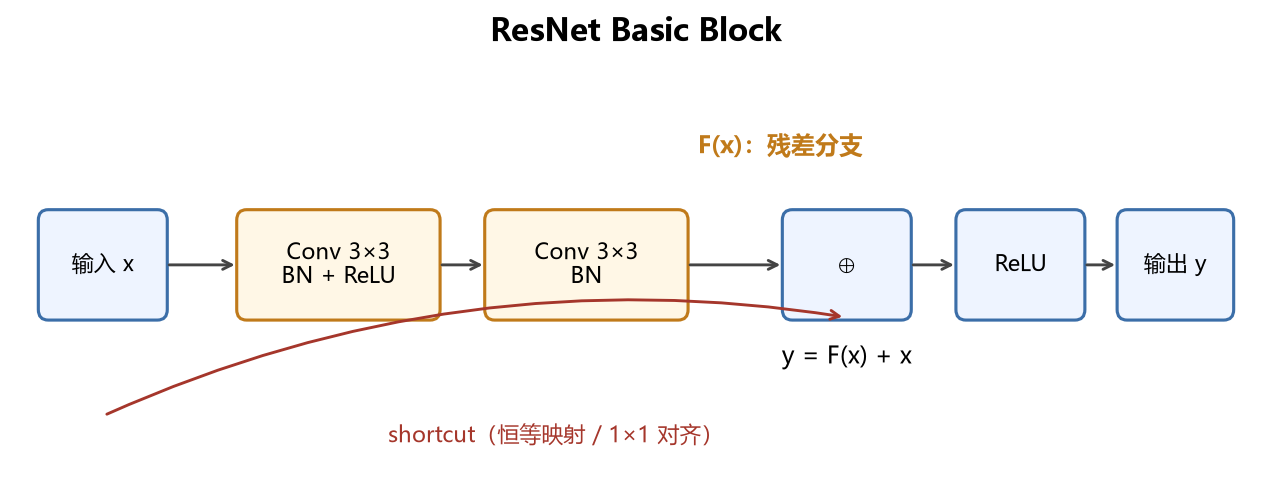
普通卷积块近似学习映射 H(x)。ResNet 改成学习残差 F(x) = H(x) - x,输出变成:
y = F(x) + x
x 通过 shortcut(捷径连接,也叫 skip connection) 直接加到输出上。如果某一层其实「什么都不用改」,网络只要把 F(x) 学成 0 就行,至少不会比恒等映射更差。
下面这张图是 ResNet 里最基础的 Basic Block(ResNet-18 / ResNet-34 用的)。Mermaid 版方便在 Markdown 里编辑,上图是同一结构的静态示意:
两个 3×3 卷积负责学 F(x),输入 x 绕过中间层直接相加。如果输入输出通道数或分辨率变了,shortcut 上会补一个 1×1 卷积做维度对齐。
更深的 ResNet-50 / ResNet-101 用的是 Bottleneck Block:先用 1×1 降维,3×3 提取特征,再用 1×1 升维。参数量更省,适合堆到上百层。
ResNet-18 长什么样
ResNet-18 名字里的 18,指的是 带权重的层数(每个卷积层算一层,不含 BatchNorm 和 ReLU)。整体可以粗分成四段:
| 阶段 | 结构 | 输出尺寸(以 224×224 输入为例) |
|---|---|---|
| stem | 7×7 Conv, stride=2 → MaxPool | 56×56 |
| layer1 | 2 个 Basic Block, 64 通道 | 56×56 |
| layer2 | 2 个 Basic Block, 128 通道, stride=2 | 28×28 |
| layer3 | 2 个 Basic Block, 256 通道, stride=2 | 14×14 |
| layer4 | 2 个 Basic Block, 512 通道, stride=2 | 7×7 |
| head | 全局平均池化 → 全连接 | 1000 类(ImageNet) |
通道数逐级翻倍、空间尺寸逐级减半,这是 CNN 里很经典的金字塔结构。ResNet 的创新不在金字塔本身,而在 每个 stage 内部的残差连接,让梯度能更顺畅地回传到浅层。
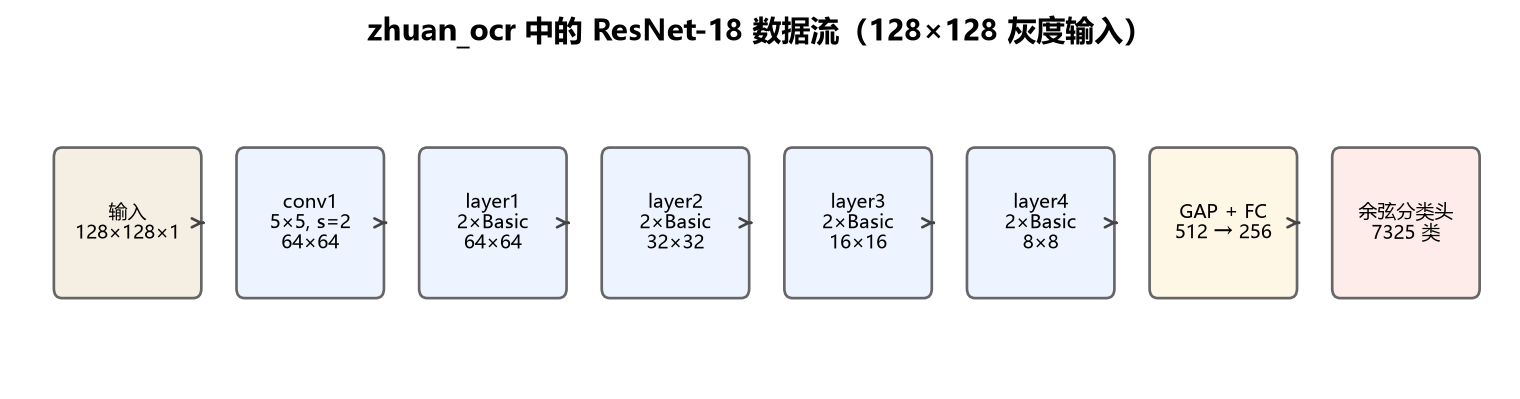
在篆书 OCR 项目里,输入只有 128×128 灰度图,各 stage 的实际尺寸如下:
它为什么好用
几个直觉上的原因:
梯度传播更顺。 反向传播时,shortcut 提供了一条「高速公路」,梯度可以少经过几层非线性,深层网络不至于在训练初期就梯度消失。
优化目标更简单。 残差形式把「学整个映射」拆成「学增量」。对很多层来说,增量接近零就是合理解,搜索空间更友好。
特征复用。 浅层学到的边缘、纹理,可以通过 shortcut 直接参与深层决策,不必每层都重新编码一遍。
正因为这些性质,ResNet 很快成了视觉任务的默认 backbone——分类、检测、分割、OCR,到处都能见到它的变体。
项目里的实际用法:篆书单字 OCR
我自己在 C:\project\zhuan_ocr 里做篆书单字识别,7325 个字符类别,输入是 128×128 的灰度图。backbone 选的就是 ResNet-18,没有从头设计网络,而是在 torchvision 预置结构上做了几处针对任务的改造。
模型看到的单字长这样——SVG 古文字和字体合成图都会归一化成统一尺寸的灰度块:

为什么选 ResNet-18
这个任务数据量不小(SVG 古文字 + 字体合成图合计八万多张),但单字图像分辨率低、结构相对简单。ResNet-18 参数量约 1100 万,比 ResNet-34/50 轻,训练和推理都快,对「单字分类」这种场景容量够用。
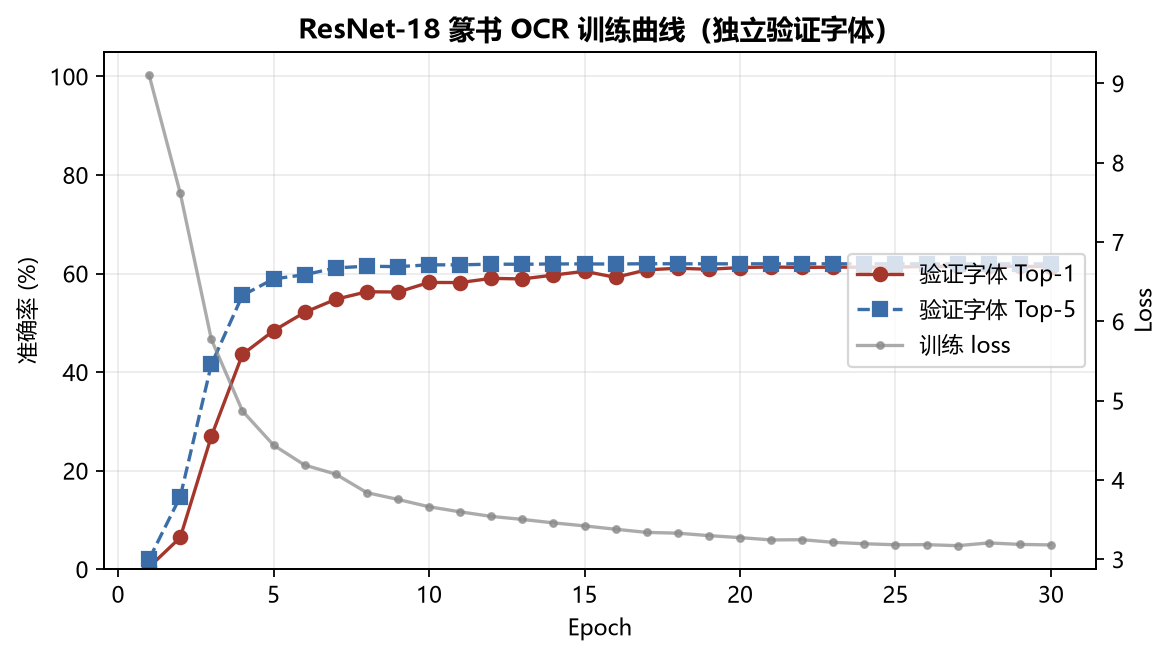
项目里做过一次排查:验证集只有 60% 左右的 Top-1,根因是 字体 cmap 声明了字符但实际渲染空白,不是 backbone 容量不够。数据清洗干净后,独立验证字体上能到 99% 以上——说明 ResNet-18 对这个任务并不「小」。
代码里改了什么
model.py 里的 GlyphRecognizer 大致做了四件事:
1. 单通道输入
ImageNet 预训练权重默认 3 通道 RGB。篆书是灰度图,把第一层 conv1 从 7×7 stride=2 改成 5×5 stride=2、1 通道进 64 通道,保留更多空间分辨率(后面会解释为什么去掉 maxpool)。
2. 去掉 maxpool
原始 ResNet 的 maxpool 会再缩小一倍特征图。128×128 的字已经很小,再 pool 笔画细节丢得厉害,所以把 maxpool 替换成 nn.Identity(),相当于跳过这一步。
3. 去掉分类头,换 embedding
network.fc 换成 Identity(),backbone 只输出 512 维特征向量。后面接 Dropout + Linear + BatchNorm,压到 256 维 L2 归一化嵌入。
4. 余弦分类头
不用普通全连接 softmax,而是 CosineClassifier:嵌入和类别权重都做 L2 归一化,logits 是缩放后的余弦相似度。跨字体泛化比纯线性头稳一些,嵌入向量还能直接拿来做近邻检索。
核心代码:
from torchvision.models import resnet18, resnet34
network = resnet18(weights=None)
network.conv1 = nn.Conv2d(1, 64, kernel_size=5, stride=2, padding=2, bias=False)
network.maxpool = nn.Identity()
features = network.fc.in_features
network.fc = nn.Identity()
self.backbone = network
self.embedding = nn.Sequential(
nn.Dropout(0.15),
nn.Linear(features, 256, bias=False),
nn.BatchNorm1d(256),
)
self.classifier = CosineClassifier(256, num_classes, scale=30.0)
配置写在 config.yaml 里,backbone: resnet18,一行就能切换成 resnet34 做对比实验。
数据流怎么走
训练时用 train.py,AMP 混合精度、label smoothing、warmup 都是常规操作。评估看 Top-1 / Top-5 和宏平均准确率,字体按整套隔离进 train / val / test,避免同字体泄漏造成虚高。
数据清洗完成后,独立验证字体上的 Top-1 / Top-5 能稳步爬到接近满分:
单字识别走 web_service.py 提供的 Web 界面:上传裁剪到单个字的图片,模型自动居中并给出 Top-5 候选。下面是对「張」字的实际推理效果,Top-1 置信度 98.0%:

用 ResNet 当 backbone 的几条经验
先确认瓶颈是不是网络。 精度上不去,先查数据标注、验证集划分、输入预处理,再考虑换 ResNet-50。我这次就是典型反例——换更大的模型救不了空白字形。
输入尺寸和 stem 要匹配任务。 小图 OCR、细粒度分类,经常需要改 conv1 核大小、去掉 maxpool,甚至把 stride 调小。预训练权重对不上就 weights=None 从头训,别硬凑三通道权重。
分类头可以换。 backbone 负责提特征,后面接线性层、余弦层、ArcFace、原型网络都行,取决于你要的是 closed-set 分类还是 open-set 检索。
ResNet 不是唯一解。 移动端可能换 MobileNet、EfficientNet;要更强特征可能上 ConvNeXt、ViT。但 ResNet 文档多、实现稳、社区案例丰富,做第一个 baseline 很合适。
小结
ResNet 解决的是「网络加深反而变差」这个优化问题,手段很简单:让层学残差,输入走 shortcut 加回来。Basic Block 和 Bottleneck Block 是两种堆叠方式,ResNet-18 用前者,轻量、好训、够用。
放到工程里,它通常不是整网照搬——改输入通道、调整 stem、换掉 fc、接一个适合业务的分类头,才是常态。篆书 OCR 这个项目就是一个具体例子:同样的 ResNet-18 骨架,配上灰度输入和余弦头,就能扛住七千多类的单字识别。
如果你也在做图像分类或 OCR,不妨先把 ResNet-18 跑通 baseline,再按数据和指标决定要不要加深、换头、或者干脆换 backbone。网络结构只是等式的一端,数据质量往往才是那个更大的乘数。
版权声明: 本文首发于 指尖魔法屋-ResNet 网络结构原理与应用实践(https://blog.thinkmoon.cn/post/996_resnet%E7%BD%91%E7%BB%9C%E7%BB%93%E6%9E%84%E5%8E%9F%E7%90%86%E4%B8%8E%E5%BA%94%E7%94%A8%E5%AE%9E%E8%B7%B5/) 转载或引用必须申明原指尖魔法屋来源及源地址!